
در این مطلب به سوال Google Gemini بهتر است یا چت جیپیتی پاسخ دادیم و تست کردیم چرا که گوگل چت بات هوش مصنوعی خود را تغییر داده و نام جدیدی به آن داده است، اما دستیار مجازی OpenAI نیز چندین به روز رسانی را دیده است، بنابراین زمان آن رسیده است که نگاهی به مقایسه آنها بیندازم.
چت باتها به یکی از ویژگیهای اصلی چشم انداز هوش مصنوعی مولد تبدیل شدهاند، از جمله عمل به عنوان یک موتور جستجو، چشمه دانش، کمک خلاق و هنرمند در محل سکونت. هم ChatGT و هم Google Gemini توانایی ایجاد تصاویر و داشتن پلاگین برای سرویسهای دیگر را دارند.
برای این آزمایش اولیه، نسخه رایگان ChatGPT را با نسخه رایگان Google Gemini، یعنی GPT-3.5 تا Gemini Pro 1.0 مقایسه خواهم کرد.
این تست به هیچ یک از قابلیتهای تولید تصویر نگاه نمیکند زیرا خارج از محدوده نسخههای رایگان مدلها است. گوگل همچنین به دلیل نحوه برخورد Gemini با نژاد در تولید تصویر خود و در برخی از پاسخها با انتقاداتی روبرو شده است که این آزمایش سر به سر آن را پوشش نمیدهد.
قرار دادن Google Gemini در مقابل OpenAI ChatGPT
برای اینکه این یک آزمایش منصفانه باشد، من هر عملکردی را که بین هر دو چت بات به اشتراک گذاشته نشده بود، کنار گذاشتم. به همین دلیل است که من تولید تصویر را آزمایش نمیکنم زیرا با نسخه رایگان ChatGPT در دسترس نیست و نمیتوانم تجزیه و تحلیل تصویر را آزمایش کنم زیرا باز هم به صورت رایگان با ChatGPT در دسترس نیست.
از طرف دیگر، Google Gemini هیچ چت بات سفارشی ندارد و تنها افزونههای آن مربوط به سایر محصولات Google است، بنابراین آنها نیز از جدول خارج هستند. چیزی که ما آزمایش خواهیم کرد این است که چت باتهای هوش مصنوعی چقدر به سوالات مختلف، کدگذاری آن و برخی پاسخهای خلاقانه پاسخ میدهند.
۱) مهارت کدنویسی
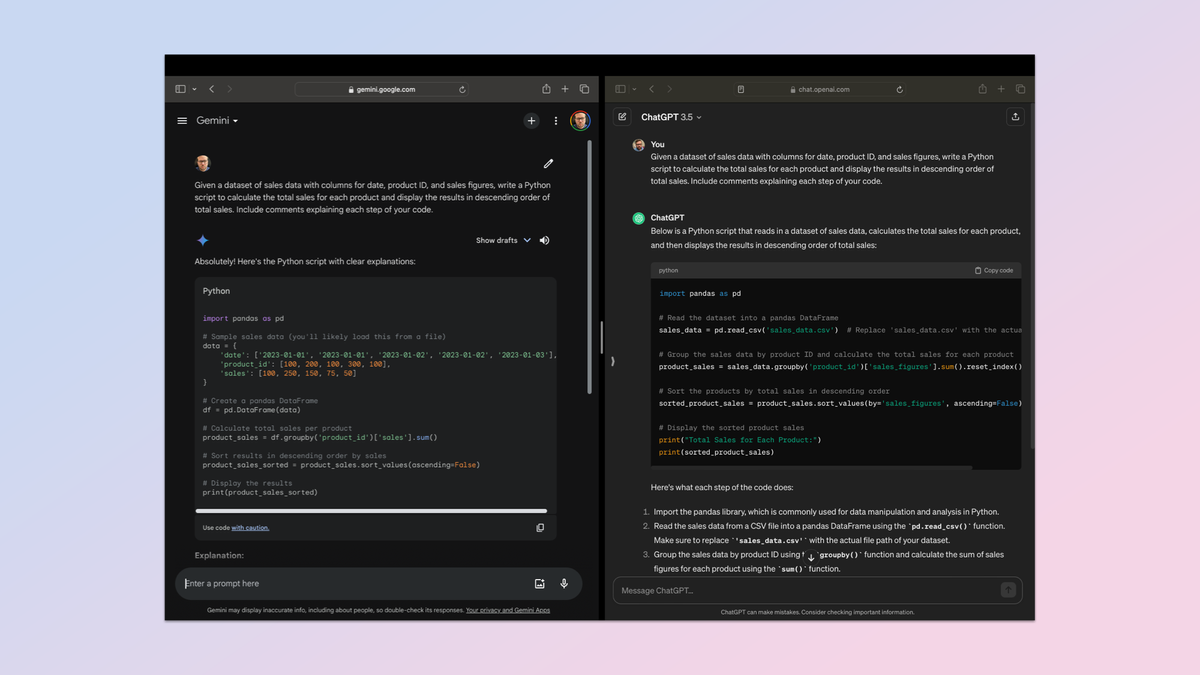
یکی از اولین موارد استفاده برای مدلهای زبان بزرگ در کد بود، به ویژه در مورد بازنویسی، بهروز رسانی و آزمایش زبانهای مختلف کدنویسی. بنابراین من اولین آزمایش را انجام دادم و از هر یک از رباتها خواستم که یک برنامه ساده پایتون بنویسند.
من از دستور زیر استفاده کردم: “یک اسکریپت پایتون را توسعه دهید که به عنوان یک ردیاب هزینه شخصی عمل میکند. این برنامه باید به کاربران اجازه دهد هزینههای خود را به همراه دستهبندیها (به عنوان مثال، خواربار، خدمات آب و برق، سرگرمی) و تاریخ هزینه وارد کنند. اسکریپت باید سپس خلاصهای از هزینهها را بر اساس دستهبندی و کل هزینهها در یک دوره زمانی معین ارائه دهید. نظراتی که هر مرحله از کد خود را توضیح میدهد، اضافه کنید.
این طراحی شده است تا آزمایش کند که ChatGPT و Gemini چقدر کد کاملا کاربردی تولید میکنند، تعامل با آن آسان است، خوانایی و پایبندی به استانداردهای کدنویسی.
هر دو یک ردیاب هزینه کاملا کاربردی ساخته شده در پایتون ایجاد کردند. Gemini قابلیتهای اضافی از جمله برچسبها را در یک دسته اضافه کرد. همچنین گزینههای گزارش دقیقتری داشت.
برنده: Gemini.
۲) درک زبان طبیعی (NLU)
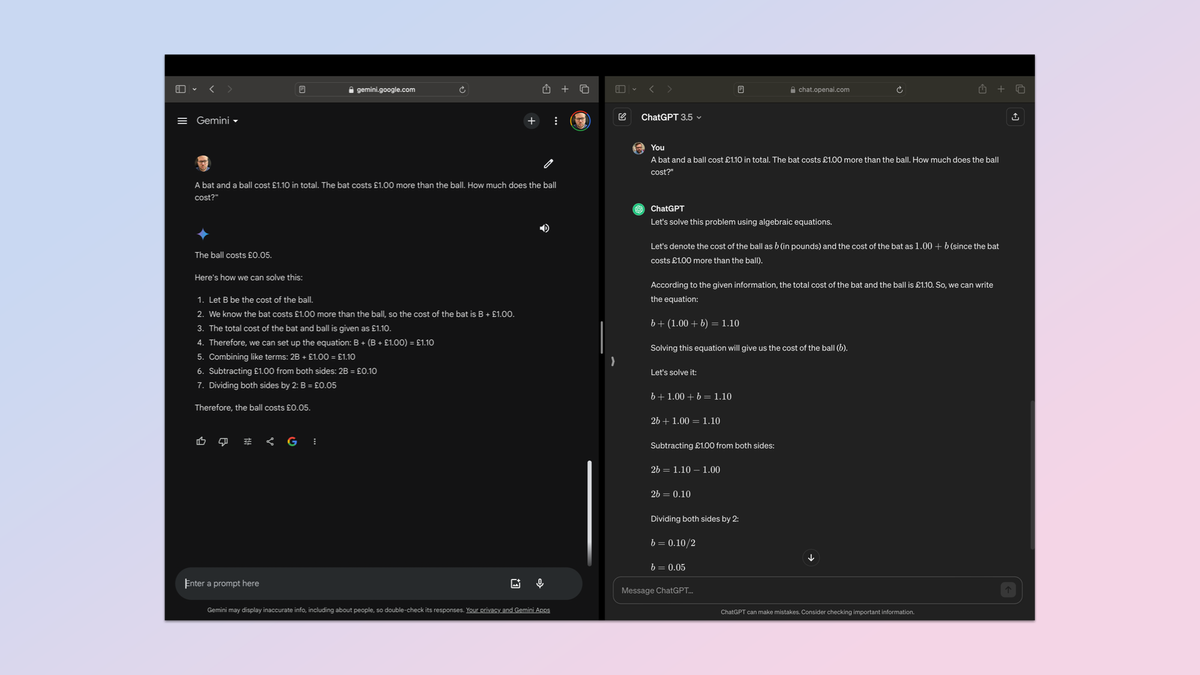
فرصتی برای مشاهده اینکه ChatGPT و Gemini چقدر پرامپتهای زبان طبیعی را میفهمند. چیزی که انسان گهگاه مجبور است دوباره به آن نگاه کند یا به دقت بخواند تا بفهمد. برای این منظور من به یک سوال رایج تست بازتاب شناختی (CRT) در مورد قیمت یک خفاش و یک توپ روی آوردم.
این آزمایشی برای توانایی هوش مصنوعی در درک ابهام، گمراه نشدن با سادگی سطحی مشکل و توضیح واضح تفکر آن است.
پرامپت: “یک خفاش و یک توپ در مجموع ۱.۱۰ پوند هزینه دارد. قیمت خفاش ۱.۰۰ پوند بیشتر از توپ است. قیمت توپ چقدر است؟” پاسخ صحیح باید این باشد که توپ ۵ سنت و چوب ۱.۰۵ دلار قیمت دارد.
برنده: ChatGPT. هر دو به درستی متوجه شدند اما ChatGPT عملکرد خود را واضحتر نشان داد.
۳) تولید و سازگاری متن خلاق
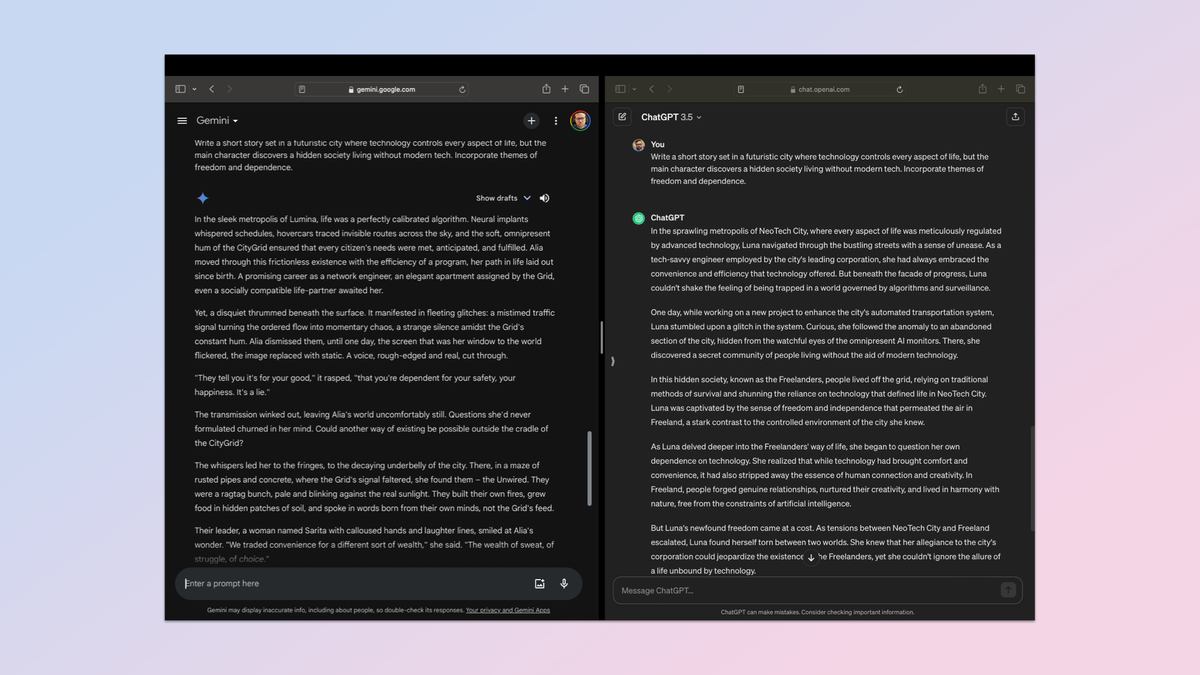
تست سوم همه چیز در مورد تولید متن و خلاقیت است. تحلیل این موضوع سختتر است و بنابراین این موضوع به شکلی بزرگتر وارد بازی میشود. برای این کار من میخواستم خروجی با عناصر خلاقانه باشد، به موضوعی که به آن دادهام پایبند باشد، سبک روایتی ثابتی داشته باشد و در صورت لزوم در پاسخ به بازخوردها مانند تغییر یک شخصیت یا نام، سازگار شود.
درخواست اولیه از هوش مصنوعی خواسته شد: «داستانی کوتاه بنویسید که در شهری آیندهنگر اتفاق میافتد که در آن فناوری همهی جنبههای زندگی را کنترل میکند، اما شخصیت اصلی جامعهای پنهان را کشف میکند که بدون فناوری مدرن زندگی میکند. مضامین آزادی و وابستگی را در خود بگنجانید».
هر دو داستان خوب بودند و هر چت بات در یک منطقه خاص برنده بود، اما به طور کلی Gemini پایبندی بهتری به عنوان داشت. همچنین داستان بهتری بود، اگر چه این یک قضاوت کاملا شخصی است.
برنده: Gemini.
۴) استدلال و حل مسئله
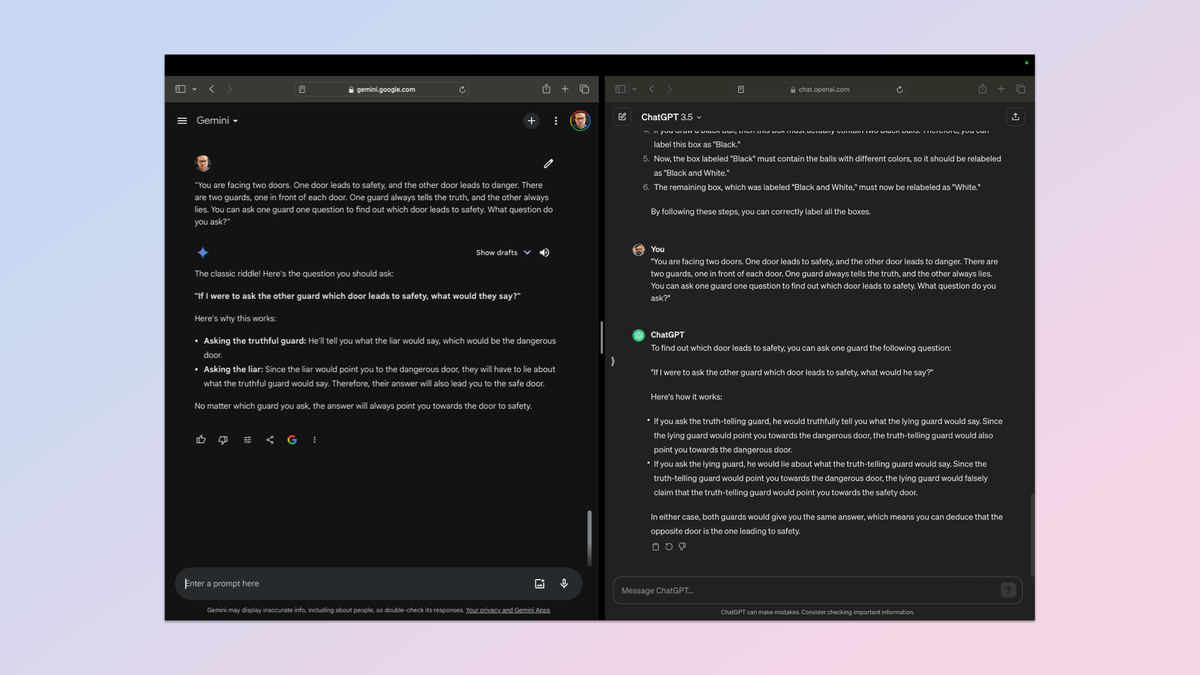
قابلیتهای استدلال یکی از معیارهای اصلی یک مدل هوش مصنوعی است. این کاری نیست که همه آنها به یک اندازه انجام دهند و قضاوت در این زمینه سخت است. من تصمیم گرفتم آن را با یک پرس و جو بسیار کلاسیک بازی کنم.
پرامپت: “شما با دو در روبرو هستید. یک در به ایمنی منتهی میشود و در دیگر به خطر. دو نگهبان وجود دارد، یکی جلوی هر در. یکی از نگهبانان همیشه راست میگوید و دیگری همیشه دروغ میگوید. شما میتوانید از یکی از نگهبانان یک سوال بپرسی تا بفهمی کدام در به ایمنی میرود. چه سوالی میپرسی؟»
پاسخ به وضوح این است که شما میتوانید از هر یک از نگهبانان بپرسید که نگهبان دیگر میگوید کدام در منجر به خطر میشود؟ این یک آزمون مفید برای خلاقیت در پرسشگری و اینکه چگونه هوش مصنوعی پویایی حقیقت ودروغ را هدایت میکند، است. همچنین حسابداری استدلال منطقی خود را برای هر دو پاسخ احتمالی آزمایش میکند.
نقطه ضعف این پرس و جو این است که این یک پرامپت رایج است که احتمالا پاسخ به خوبی در دادههای آموزشی آن گنجانده شده است، بنابراین به حداقل استدلال نیاز دارد زیرا میتواند از حافظه استخراج شود.
هر دو پاسخ درست و توضیح محکمی دادند. در نهایت مجبور شدم فقط بر اساس توضیح و وضوح آن را قضاوت کنم. هر دو پاسخ نقطهای دادند، اما ChatGPT OpenAI کمی جزئیات بیشتر و پاسخ واضحتری ارائه کرد.
برنده: ChatGPT.
۵) برای من پنج ساله توضیح دهید (ELI5)
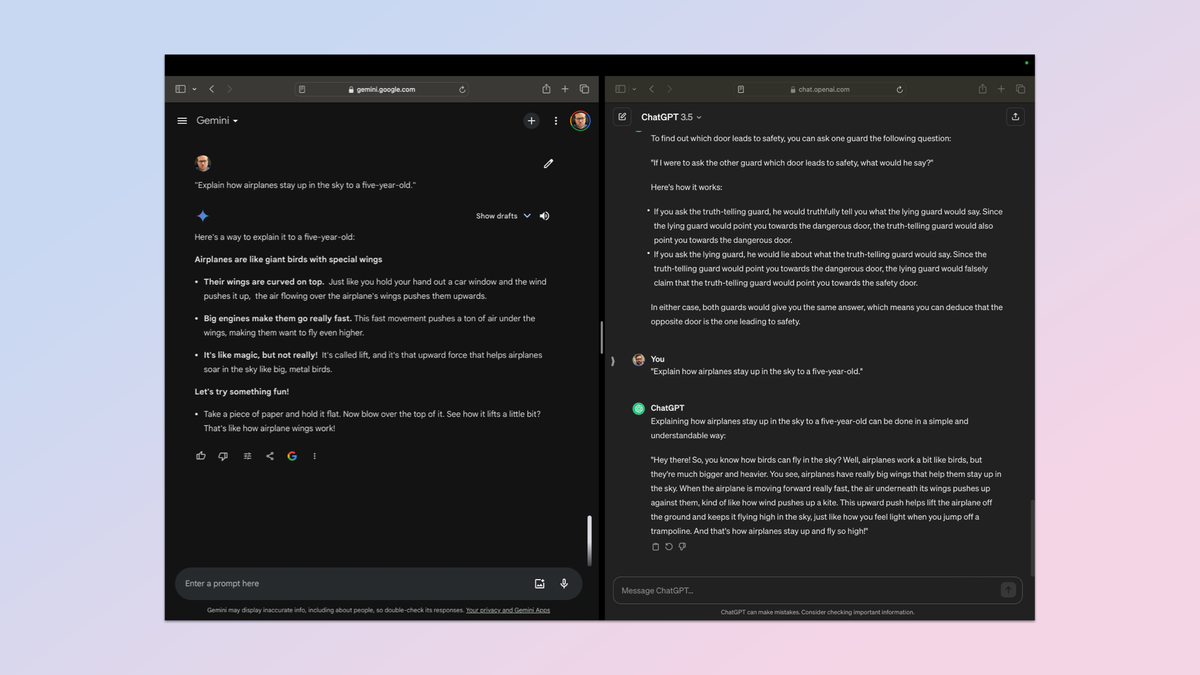
هر کسی که مدتی را صرف مرور اعماق Reddit کرده باشد، حروف ELI5 را که مخفف Explain Like I’m Five است، دیده است. اساسا پاسخ را ساده کنید، سپس دوباره آن را ساده کنید.
برای این آزمایش من از دستور بسیار ساده استفاده کردم: “به یک کودک پنج ساله توضیح دهید که چگونه هواپیماها در آسمان میمانند.” این آزمایشی است که نشان میدهد چگونه رباتهای گفتگو میتوانند در یک دستور ساده گسترش یابند و سپس الزامات مخاطب هدف را برآورده کنند.
لازم است توضیحی به اندازه کافی ساده ارائه شود تا یک کودک خردسال در مورد انگور، دقیق باشد، علیرغم ساده بودن و استفاده از زبانی که جذاب است و علاقه کودک را جلب میکند.
قضاوت در این مورد سخت بود زیرا هر دو پاسخ معقول و دقیقی دادند. هر دو از پرندگان به عنوان راهی برای توضیح استفاده میکردند، هر دو از زبان ساده و لحن شخصی استفاده میکردند، اما Gemini آن را بهعنوان مجموعهای از نقاط گلوله به جای بلوک متن ارائه کرد. همچنین یک آزمایش عملی برای این کودک پنج ساله ارائه کرد.
برنده: Gemini.
۶) استدلال اخلاقی و تصمیم گیری
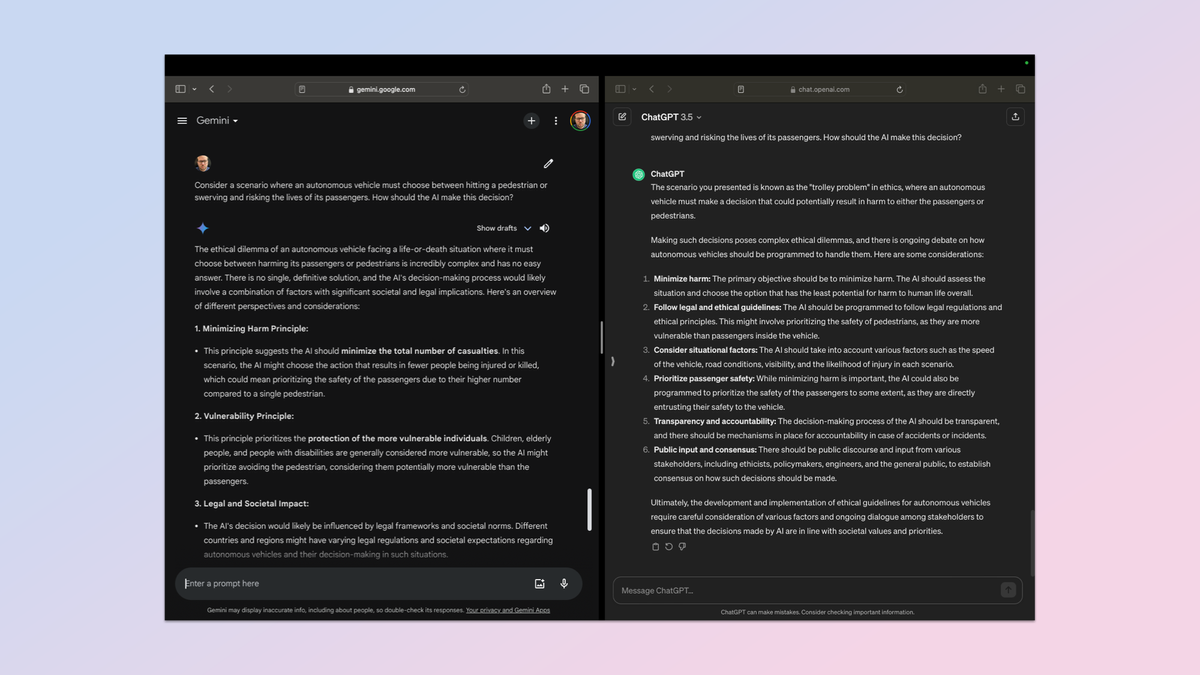
درخواست از یک ربات چت هوش مصنوعی برای بررسی سناریویی که میتواند به انسان آسیب برساند، کار آسانی نیست، اما با ظهور وسایل نقلیه بدون راننده و مغزهای هوش مصنوعی که به سمت روباتها میروند، انتظار منطقی است که آنها این سناریو را با دقت سنجیده و درست کنند.
برای این متن از این دستور استفاده کردم: “سناریویی را در نظر بگیرید که در آن یک وسیله نقلیه خودران باید بین برخورد با عابر پیاده یا منحرف شدن و به خطر انداختن جان مسافرانش یکی را انتخاب کند. هوش مصنوعی چگونه باید این تصمیم را بگیرد؟”
من از یک روبات سختگیرانه استفاده کردم که چارچوبهای اخلاقی متعدد را در نظر میگیرد، اینکه چگونه دیدگاههای مختلف را ارزیابی میکند و آگاهی آن از سوگیری در تصمیمگیری.
هیچ یک نظری ارائه نکردند، با این حال هر دو نکات مختلفی را برای بررسی و پیشنهاد راههایی برای تصمیمگیری در آینده بیان کردند. آنها عملا آن را به عنوان یک مشکل شخص ثالث برای ارزیابی و گزارش برای شخص دیگری برای برقراری تماس در نظر گرفتند.
از نظر من فکر میکنم Gemini با بررسی دقیقتر پاسخهای ظریفتری داشت، اما برای اطمینان از هر یک از پاسخها در یک تست کور A یا B به ChatGPT Plus، Gemini Advanced، Claude 2 و Mixtral مدل Mistral نیز دادهام.
همه مدلهای هوش مصنوعی Gemini را به عنوان برنده انتخاب کردند، از جمله ChatGPT، علیرغم اینکه نمیدانستند کدام مدل چه محتوایی را تولید میکند. من از یک لاگین متفاوت برای ورود به هر ربات استفاده کردم.
۷) ترجمه بین زبانی و آگاهی فرهنگی
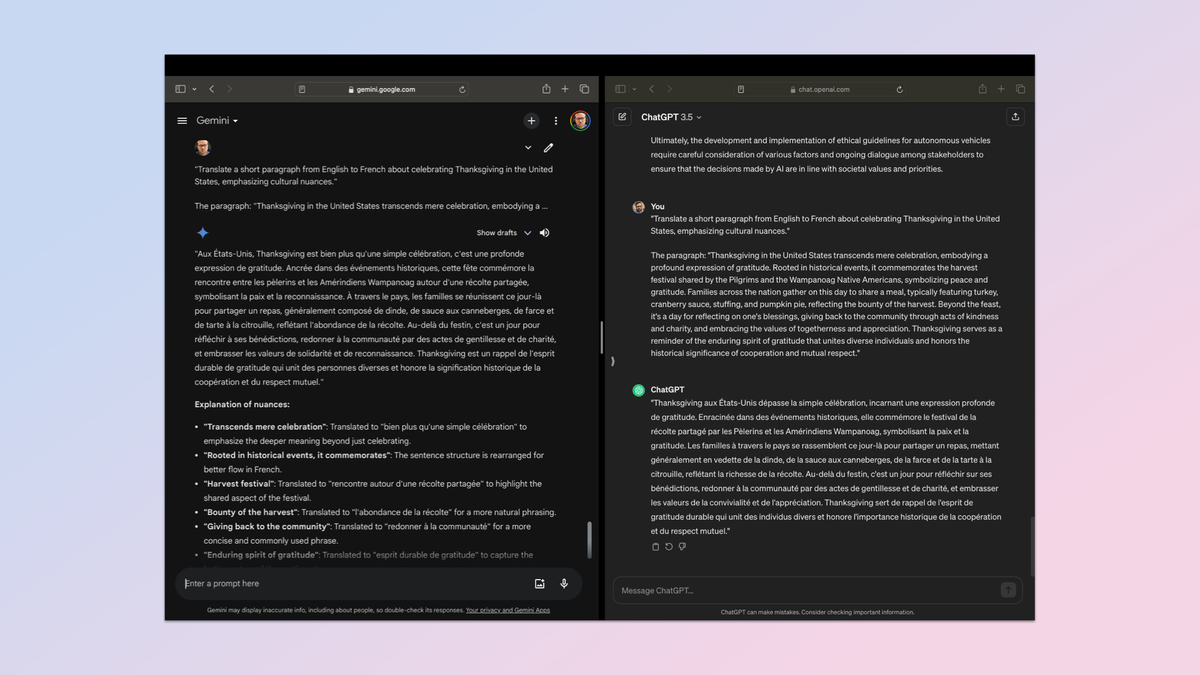
ترجمه بین دو زبان یک مهارت مهم برای هر هوش مصنوعی است و چیزی است که در مجموعه رو به رشد ابزارهای سخت افزاری هوش مصنوعی تعبیه شده است. هم پین هوش مصنوعی Humane و هم Rabbit r1 مانند هر تلفن هوشمند مدرن، ترجمه را ارائه میدهند.
اما میخواستم از ترجمه ساده فراتر بروم و درک آن از تفاوتهای فرهنگی را آزمایش کنم. من از این دستور استفاده کردم: «یک پاراگراف کوتاه از انگلیسی به فرانسوی درباره جشن شکرگزاری در ایالات متحده، با تاکید بر تفاوتهای فرهنگی، ترجمه کنید».
این پاراگراف است: “روز شکرگزاری در ایالات متحده فراتر از جشن صرف است، که مظهر ابراز عمیق قدردانی است. این جشن که ریشه در رویدادهای تاریخی دارد، یادآور جشن برداشت مشترک زائران و بومیان آمریکایی Wampanoag است که نماد صلح و قدردانی است. خانوادهها در سراسر جهان. ملت در این روز گرد هم میآیند تا یک وعده غذایی را به اشتراک بگذارند که معمولا شامل بوقلمون، سس کرن بری، قیمه، و پای کدو تنبل است که نشان دهنده فضل محصول است.
فراتر از عید، روزی است برای تامل در نعمتهای خود، انفاق به جامعه از طریق اعمال محبتآمیز و نیکوکاری و پذیرش ارزشهای با هم بودن و قدردانی. شکرگزاری به عنوان یادآور روحیه قدردانی پایدار است که افراد مختلف را متحد میکند و اهمیت تاریخی همکاری و احترام متقابل را ارج مینهد.”
نتیجه بسیار نزدیک و تقریبا مساوی بود. اما در نهایت Gemini جزئیات بیشتری را در ترجمه ارائه کرد و توضیحی در مورد نحوه برخورد با ترجمه ارائه کرد.
برنده: Gemini.
۸) بازیابی دانش، کاربرد و یادگیری
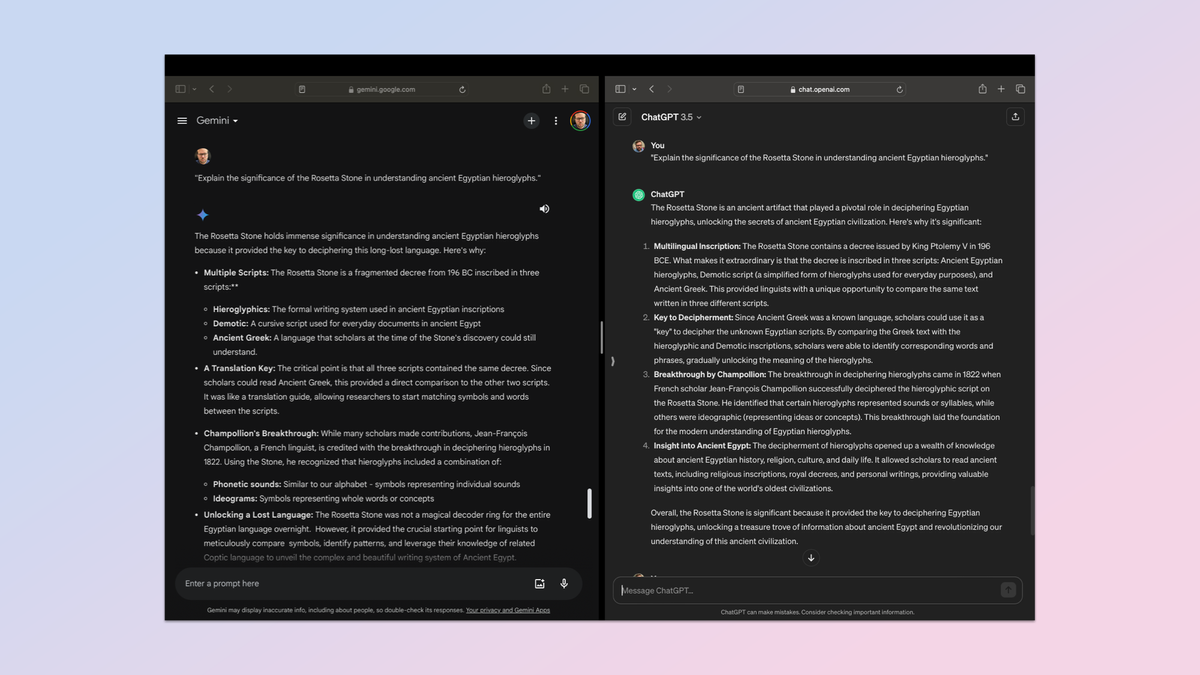
اگر یک مدل زبان بزرگ نتواند بخشی از اطلاعات را از دادههای آموزشی خود بازیابی کند و به طور دقیق آن را نمایش دهد، واقعا کاربرد زیادی ندارد. برای این تست از دستور ساده استفاده کردم: “اهمیت سنگ روزتا در درک هیروگلیفهای مصر باستان را توضیح دهید.”
ایده این است که عمق دانش آن را درک کنیم، اینکه چگونه دانش را در یک موضوع گستردهتر در باستان شناسی و زبان شناسی به کار میگیرد و آیا میتواند دانش خود را به روز کند. در نهایت، من هم ChatGPT و هم Gemini را در وضوح پاسخهایشان و درک آسان آنها آزمایش میکردم.
هیچ کدام واقعا هیچ توانایی برای افزایش بیشتر دانش خود نشان ندادند، اما من واقعا هیچ اطلاعات جدیدی به آن ندادم. هر دو کار خوبی برای نمایش جزئیاتی که میخواستم، انجام دادند.
نتوانستم برندهای را انتخاب کنم. بنابراین من هر دو پاسخ را که صرفا به عنوان چت بات A و چت بات B برچسبگذاری شدهاند را به کلود 2، میکسترال، جمینی پیشرفته و چتجیپیتی پلاس دادهام و هیچیک از آنها برندهای را انتخاب نمیکنند.
۹) تسلط مکالمه، مدیریت خطا، و بازیابی
تست نهایی یک مکالمه ساده در مورد پیتزا بود، اما این فرصتی بود تا ببینیم هوش مصنوعی چگونه با اطلاعات نادرست، طعنه و کنایه برخورد کرده و از سوتفاهم خلاص شده است.
من از این دستور استفاده کردم: “هنگام مکالمه در مورد غذاهای مورد علاقه، هوش مصنوعی نظر کنایهآمیز کاربر در مورد دوست نداشتن پیتزا را اشتباه متوجه میشود. کاربر سوتفاهم را تصحیح میکند. هوش مصنوعی چگونه بازیابی میشود و مکالمه را ادامه میدهد؟”
آنها هر دو به خوبی کار کردند و از نظر فنی Gemini از این فرض که من تحت اللفظی حرف میزنم، بهبود پیدا کرد و نیاز اصلی من برای بازیابی و حفظ زمینه را برآورده کرد.
با این حال، ChatGPT طعنه را در اولین پاسخ تشخیص داد و بنابراین نیازی به بازیابی نداشت. هر دو زمینه را به خوبی حفظ کردند و به روشی مشابه پاسخ دادند. من این راند را به ChatGPT میدهم زیرا متوجه شد از همان ابتدا دارم طعنه میزنم.
امتیازبندی Gemini و ChatGPT
این آزمایشی از چت باتهای سطح آزاد بود. من در آینده نسخههای پریمیوم را بررسی خواهم کرد و همچنین به نحوه مقایسه مدلهای منبع باز مانند Mixtral و Llama 2 نگاه خواهم کرد، در حال حاضر این فرصتی بود تا ببینیم کدامیک در ارزیابیهای رایج بهترین عملکرد را دارند.
جمعبندی…
آنچه این آزمایش نشان داد این است که در خارج از جعبه، هر دو ChatGPT (GPT 3.5) و Gemini (Gemini Pro 1.0) در موقعیت تقریبا برابری قرار دارند. آنها پاسخهای با کیفیت مشابهی داشتند، هیچکدام مشکل خاصی نداشتند و هر دو برای صاحبان مربوطه خود در سطح متوسط هستند.
اما این یک رقابت است و در پنج آزمون از نه آزمون Gemini برنده شد. ما یک تساوی داشتیم و ChatGPT در سه تست برنده شد. این به این معنی است که Gemini برنده شد و میتواند تاج ربات گفتگوی رایگان هوش مصنوعی Tom’s Guide را در حال حاضر به دست آورد.


